Author: Brandon Bertelsen
Last updated: 2023-01-18
Codebooks!
A codebook is used as a reference to document the contents of a survey by displaying unweighted counts and other types of survey metadata that may be important to someone using those data outside of the context of the crunch web application or other toplines/crosstabs prepared by crunchtabs.
Generating Codebooks
You must be an editor of a dataset to make a codebook from a crunch dataset. In addition, the dataset must be unweighted. If your dataset is being actively used by clients it is recommended that you create a fork.
Creating a codebook from a crunch dataset is easy. In the examples below a codebook is created using the example dataset built into crunch.
library(crunchtabs)
login()
# If you already have an example dataset available in your account
# ds <- loadDataset("Example dataset")
ds <- newExampledataset()
writeCodeBookLatex(ds)
Codebook Example
By default, if you supply a dataset to the the function writeCodeBookLatex it will name the resulting file after the dataset as well as set a title on the document with the same moniker. The resulting PDF document will be automatically opened after a short delay as the dataset is manipulated and written to PDF.
In some cases, your dataset may have an extremely long or otherwise problematic name, in this case, you can use the URL to the dataset.
writeCodeBookLatex(ds, url = "https://api.crunch.io/datasets/<dataset-id>")Appendices: If your data contain a categorical question with more than 20 categories, it will be pushed into an appendix by default. You can control this behavior by using the parameter
appendx = FALSE
Options
There are a number of optional settings that you can control such as: displaying a table of contents, a sample description, changing the title or subtitle, or adding a logo.
Table of Contents
A table of contents can be added by using the table_of_contents argument. Setting this argument to TRUE, provides a table of contents that shows the variable alias (crunch::alias) followed by a short description of the variable that is derived from the crunch name (crunch::name) as well as the page number where the related codebook summary can be found.
writeCodeBookLatex(ds, table_of_contents = TRUE)
Table of contents
Appendices
By default, an appendix will be created for any categorical question that has more than 20 categories. This is done with the intent to avoid useless scrolling by the user. However, should you not care for an appendix you can use the argument appendix = FALSE. If you choose to not use an appendix, it may also be desirable to set suppress_zero_counts=TRUE to avoid long presentations of empty categories in dataset order.
writeCodeBookLatex(ds, appendix = FALSE)Titles, Sub-headings and other Descriptives
Currently you can change the title, subtitle and provide descriptives for the elements: sample description and field window.
writeCodeBookLatex(
ds[1],
title = "Your Title Here",
subtitle = "Your Subtitle Here",
field_period = "Feb 2021 - Mar 2021",
sample_desc = "US Voting Adults",
preamble = "You can enter arbitrary \\textbf{\\emph{tex}} in the preamble, but it must be double escaped. "
)
Table of contents
Logos
Default logos for YouGov and YouGov Blue have been included in the package for easy reference. If neither suit your purposes you can also specify a path to a PNG formatted image. The recommendation is an image size of 50 pixels in height and 250-350 pixels in width. If you would like your sub-brand logo added to the package please submit an issue on github (https://github.com/Crunch-io/crunchtabs/issues)
writeCodeBookLatex(ds, logo = "yougov")
# writeCodeBookLatex(ds, logo = "ygblue")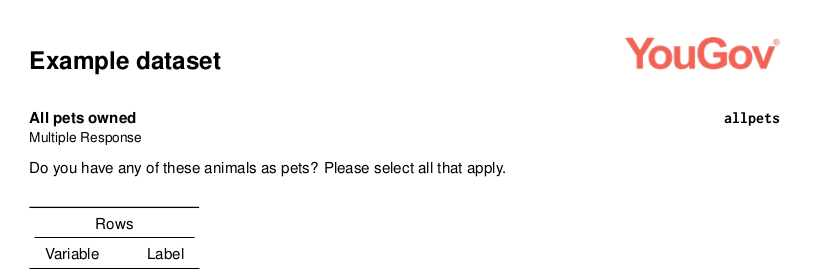
Table of contents
Suppressing Zeroes
Although not recommended, there are some questions that have a significant amount of zero-filled categories (country of residence for example). This can lead to the end-user of the codebook scrolling through pages and pages of zero filled categories. You can suppress zeroes using the following:
writeCodeBookLatex(ds, suppress_zero_counts = TRUE)Table Alignment
The table alignment on the page can be adjusted to one of: “l” for left (the default), “c” for center, or “r” for right by using the position parameter.
writeCodeBookLatex(ds, position = "c")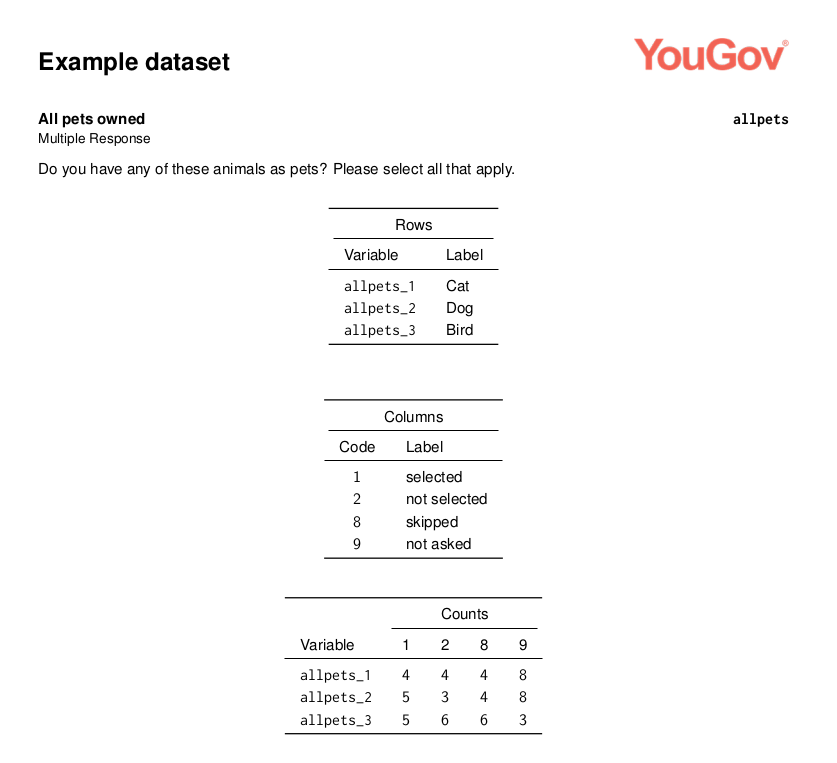
Centered codebook
Generating Codebooks from Generic Data
You can also create a codebook from a generic dataset but you are required to create the meta data yourself. Below, we will discuss the format of the meta data and what you need to do to put it together.
Your meta data should include the following:
- alias: The short code for the name of the column
- descrption: A long description of the contents of the variables. If this is survey data, your question text would go here.
- name: This is a short name for the variable that is designed to provide flavor for the alias but no detail as in the description.
- notes: This is descriptive text that identifies a subset.
- recode: Required column but optional fill. Used in other processes where raw data requires additional manipulation or recoding.
Important: We parse the meta data file to create the codebook, we don’t parse the data other than for summarization, columns/variables not specified in the meta data are ignored.
library(crunchtabs)
ds <- datasets::iris
meta <- data.frame(
alias = c(
"Sepal.Length",
"Sepal.Width",
"Petal.Length",
"Petal.Width",
"Species"
),
name = c(
"Sepal Length",
"Sepal Width",
"Petal Length",
"Petal Width",
"Iris Species"
),
description = c(
"The length of the flower's sepal",
"The width of the flower's sepal",
"The length of the flower's petals",
"The width of the flower's petals",
"The iris species"
),
notes = rep("", 5),
recode = rep(NA, 5),
stringsAsFactors = FALSE
)
writeCodeBookLatexGeneric(
ds[c(1,5)],
meta = meta[c(1,5),],
title = "Edgar Anderson's Iris Data",
subtitle = "The data were collected by Anderson, Edgar",
field_period = "1935",
sample_desc = "The irises of the Gaspe Peninsula",
preamble = "This famous (Fisher's or Anderson's) iris data set gives the measurements in centimeters of the variables sepal length and width and petal length and width, respectively, for 50 flowers from each of 3 species of iris. The species are Iris setosa, versicolor, and virginica.",
table_of_contents = TRUE,
)
Codebook generic example 001
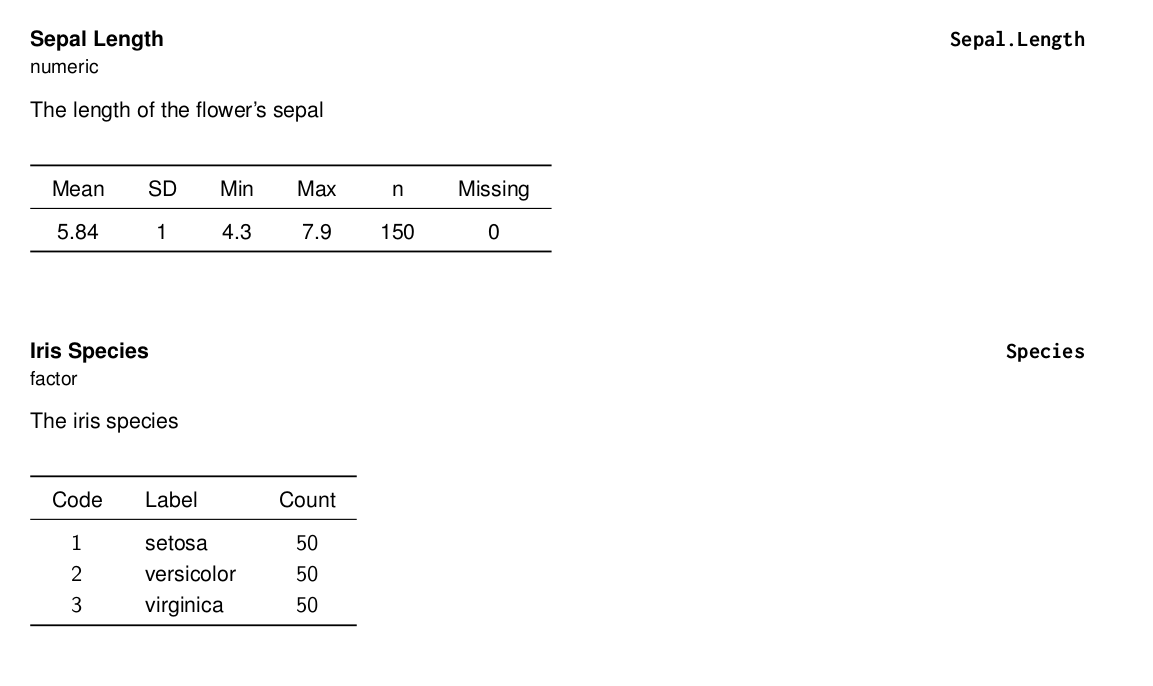
Codebook generic example 001